 How to automate naming and splitting of scanned delivery notes
How to automate naming and splitting of scanned delivery notes
Learn how to improve zone processing using advanced settings in ImageRamp Batch
Extracting content from existing scanned documents can save significant time when done right. How can we obtain the highest degree of automation out of our scanned documents?
Delivery Tickets Use Case -
In this scenario, a company scans several delivery tickets at the same time. The tickets contain a unique text identifier including a date and three part numbers encased in square brackets. Since these are newly scanned, OCR processing is required to add intelligence to the scanned image files. Each delivery note has a specific string of text that is contained within square brackets ie "[[028573-502838-928439]]. And the desire is to automate the naming of the resulting delivery tickets.
Some of the common issues inherent with this process are multiple.
- Inconsistency of the location of the text,
- OCR tends to misread numbers as letters (1 as I, 5 as S, 8 as B and 0 as O).
- It is costly to scan each document individually, so splitting is a desired output.
We will walk through the steps of ensuring the highest degree of automation with ImageRamp in this article.
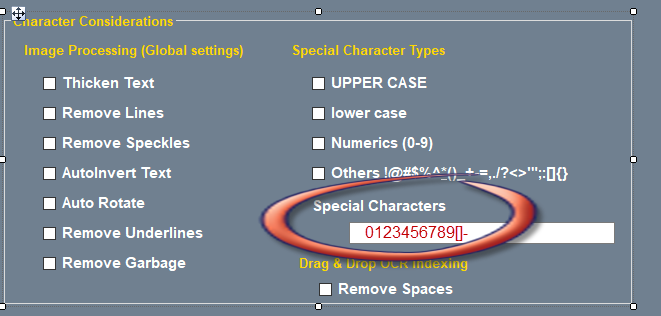
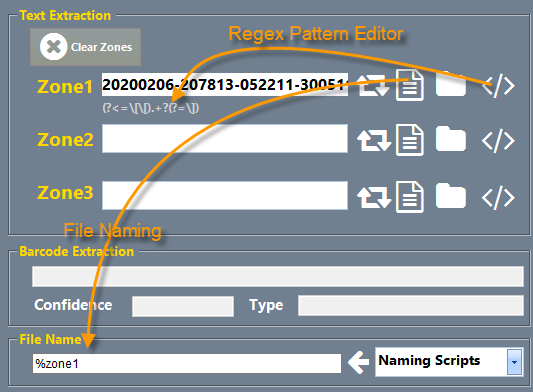
| Step 1 OCR Fine Tuning - One of the first things to do is to set the OCR engine to only recognize specific characters. All text identified in the region of interest will only result in these characters. You can enter any specific characters or use the built in character types found in the OCR Settings panel. | Step 2 Regular Expressions - We can also take advantage of the uniqueness of the text and Regular Expression. This offers a way to pinpoint the exact text patterns we want to extract. We can be very specific. In this script we are looking for "[[" at the beginning of a string and "]" at the end of the string and extracting everything in between. | Step 3 Define our Zone - Now select the icon to define a rectangular zone from which we will perform the OCR extraction of text. All text will utilize the character definitions defined earlier and will use the regular expression to extract just the specific text we desire. |
 |
 |
 |
|
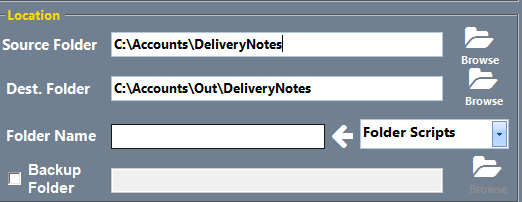
Step 4 - File Naming and paths we can finish the document type configuration by defining how the file is to be named using barcode, system or text extraction keywords, and defining where the files will be coming from and go to. |
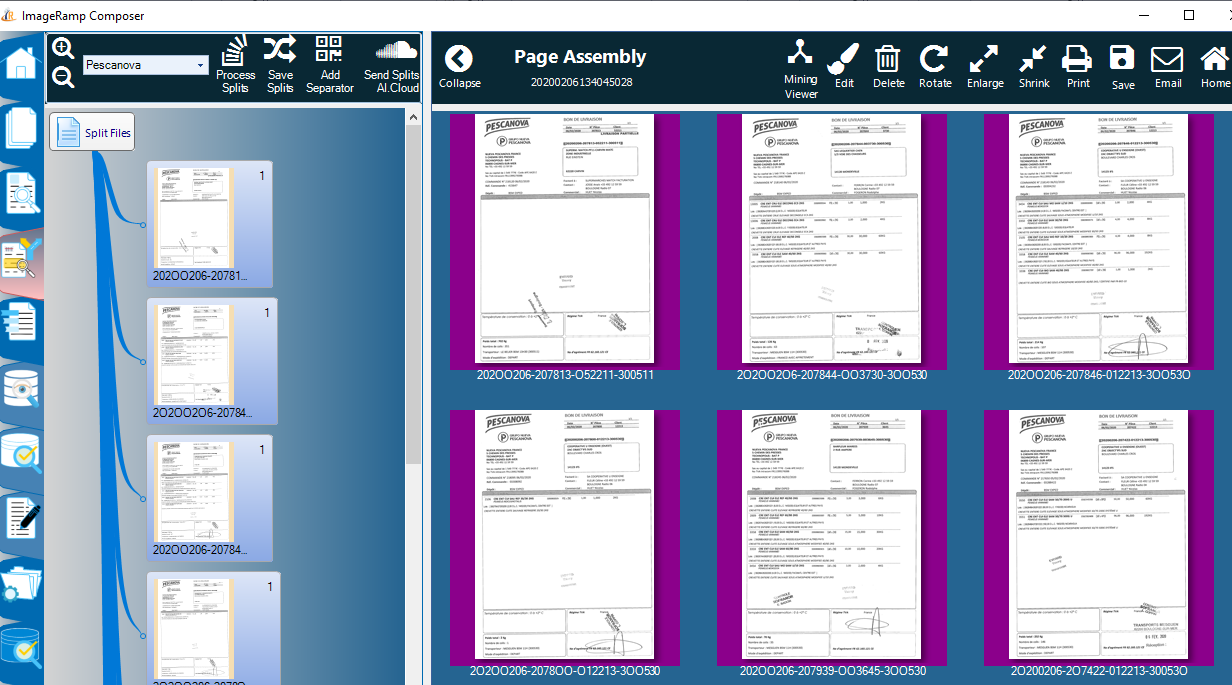
Step 5 - Processing the splits - Once set up, we can now load individual files or set up folder watching to process files. Here we've loaded a 17 page scan and processed the splits in accordance with our newly defined delivery notes document type. | Step 6 - The Processed output - We can now see the results of our processing with all numeric values extracted from the OCR zones. |
 |
 |
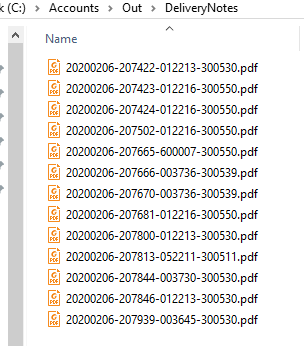 |
Content Data Mining
 Files that contain text can be mined using various data mining techniques. If your documents are scanned pages, you can use full page (text) OCR tools, to turn them into files that can take advantage of this. PDF print streams is another method used to produce the source data for invoice runs or other AP/AR functions that can then be mined for data and document splits. Or existing text-based office documents such as spreadsheets and word documents can also be mined using these techniques. The use of regular expression scripts (regex) has found its way into this arena by providing a powerful tool to help identify keywords or the actual string of text that is desired for capture. The scripting process can look for words with specific characters, lengths, character types, or preceding keywords.
Files that contain text can be mined using various data mining techniques. If your documents are scanned pages, you can use full page (text) OCR tools, to turn them into files that can take advantage of this. PDF print streams is another method used to produce the source data for invoice runs or other AP/AR functions that can then be mined for data and document splits. Or existing text-based office documents such as spreadsheets and word documents can also be mined using these techniques. The use of regular expression scripts (regex) has found its way into this arena by providing a powerful tool to help identify keywords or the actual string of text that is desired for capture. The scripting process can look for words with specific characters, lengths, character types, or preceding keywords.
Regex can also play a role in Index Field Validation. If an inventory item should contain three alpha characters followed by five numbers, advanced indexing solutions can use regex to recognized this pattern and reject all documents with items not meeting this rule. The document can be tagged for manual inspection before further index processing is done
Optical Character Recognition and Indexing
W ith OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing. With zonal OCR, document areas are specifically identified for OCR capture. Additionally, drag-and-drop OCR allows an operator to highlight document text which is automatically OCR'd and dropped into index fields.
ith OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing. With zonal OCR, document areas are specifically identified for OCR capture. Additionally, drag-and-drop OCR allows an operator to highlight document text which is automatically OCR'd and dropped into index fields.
Learn more about automated indexing at ImageRamp.
With most data capture solutions to create a full-text index, users simply select the output file format as a “searchable PDF.” This uses OCR technology to create a PDF file with two layers, an image layer and a text layer that can be used for full-text searching. Your application may label this as “make searchable”, “apply OCR”, “text-under-image” or “searchable PDF.”
I