|
|
 |
|
Download our most popular solution for your document processing needs. You'll get a free version of ImageRamp Composer, a trial of ImageRamp Batch plus several fully functioning Free tools to produce OCR'd PDF, Create Barcode Separation Sheets, assemble PDF files and Validate barcode splits. |

How to Fine Tune OCR Extraction using Regular Expressions
The Case for Automated Data Capture
 Extracting specific data items (often called metadata) from documents can be an extremely expensive and time consuming task. Often document scans are sent offshore to large outsourcing data entry companies where the data is keyed by hand. There are however various drawbacks to this approach as follows;
Extracting specific data items (often called metadata) from documents can be an extremely expensive and time consuming task. Often document scans are sent offshore to large outsourcing data entry companies where the data is keyed by hand. There are however various drawbacks to this approach as follows;
- Document security maybe compromised
- A delay is introduced into workflow processes
- Compared to automated extraction, manual indexing is a slow process
- Manual indexing doesn’t scale well with large projects
- Manual indexing has the potential to introduce errors into the data
Even with the proliferation of scanning, a large portion of business transactions still rely on paper-based documents. It is estimated that 85% of invoices are still issued on paper and we can safely assume that being the case, purchase orders and statements are of a similar order of magnitude. Also of course there is a mountain of existing paper and microfilm stored in huge warehouses!
In this article we will explain what regular expressions are and how they can help you extract the data you need from your documents, quickly, efficiently and without manually keying that data. Please note we will provide examples of regular expressions; but this is not intended as a comprehensive tutorial on creating regular expressions.
So, What are Regular Expressions?
 Regular expressions (regex) provide a fast and powerful method to search, extract and replace specific data found within documents.
Regular expressions (regex) provide a fast and powerful method to search, extract and replace specific data found within documents.
Regular expressions are essentially a special text string for describing a search pattern. You could think of regular expressions as extremely powerful wildcards.
A simple regular expression might look something like this:
^\s{1,3}[A-Z0-9]XYZ
Let’s break this expression down and see what each element does:
|
^ |
Start at the beginning of a string or line |
|
\s{1,3} |
Find a space that occurs between 1 and 3 times |
|
[A-Z0-9]* |
Find any character in the range A-Z and 0-9, the “*” is the instruction to find as many occurrences as possible. |
|
XYZ |
Find the literal characters “XYZ” |
If we had the value “ AZR8987XYZ” in our document at the start of a line we would get a match whereas if we had “ AZR898XY” we wouldn’t get a match.
Regular expressions are extremely flexible and patterns can be constructed to match almost anything. For text commonly found in documents such as dates,, SSNs, ZIP codes etc., patterns are freely available on the Internet. Here are some examples:
ZIP Codes - ^(?!00000)(?(?\d{5})(?:[ -](?=\d))?(?\d{4})?)$
US Phone Number - ^([0-9]( |-)?)?(\(?[0-9]{3}\)?|[0-9]{3})( |-)?([0-9]{3}( |-)?[0-9]{4}|[a-zA-Z0-9]{7})$
Credit Card - (^(4|5)\d{3}-?\d{4}-?\d{4}-?\d{4}|(4|5)\d{15})|(^(6011)-?\d{4}-?\d{4}-?\d{4}|(6011)-?\d{12})|(^((3\d{3}))-\d{6}-\d{5}|^((3\d{14})))
Real World Examples
Let's take a look at some real world examples of data we might need to capture and extract. Here is a partial invoice where I might need to capture the "Catalogue Number":
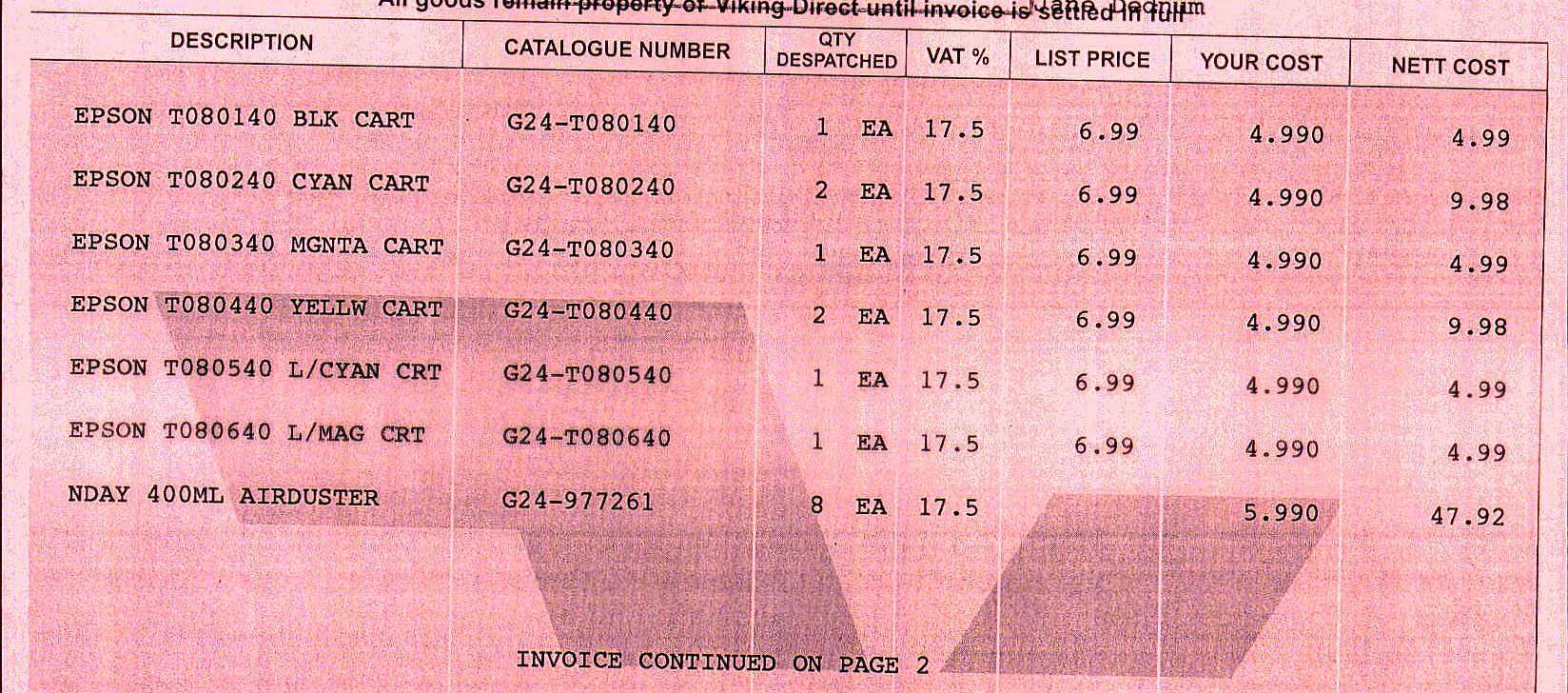
In order to start constructing a regular expression we have to use what we know from the data in front of us as well as making some assumptions. During testing we can refine the regular expression.
In this example we can assume from the document that the catalogue number has the format of a single uppercase letter, followed by 2 digits then a hyphen followed by a single uppercase letter and 6 digits or just 6 digits. We could use the regex of [A-Z]\d{2}-[A-Z]{0,1}\d{6} extract the data:
Let's again break this down:
|
[A-Z] |
Find a character from A-Z, the absence of a quantifier specification,“{}”, assumes we are only looking for 1 character |
|
\d{2} |
Find exactly 2 digits |
|
- |
Find the literal character “-“ |
|
[A-Z]{0,1} |
Find a character A-Z between 0 and 1 repetitions |
|
\d{6} |
Find exactly 6 digits |
This is just one way of writing a regular expression for this example although there are various ways it could be written. If we should subsequently find that the last portion of the catalogue number might contain 4 to 6 digits, we could simply amend it as follows [A-Z]\d{2}-[A-Z]{0,1}\d{4,6}.
Using ImageRamp Batch and Regular Expressions to Extract Data
ImageRamp Batch offers a simple-to-use folder processing tool that accelerates getting your files into various EMR, Document Management or other secure storage environments. It uses existing MFP copiers, scanners, or even pre-existing PDF files to assign specific tasks to specific folders for
unattended processing.
ImageRamp Batch provides a host of features to efficiently and effectively extract and use data from both paper and electronic-based documents. Features include:
- Image processing for clean up and adaptive thresholding
- OCR
- Barcode reading (1D and 2D)
- Full text OCR to PDF
- PDF rights management and encryption
- Document splitting and routing based on barcodes and page content
As an example, we might want to extract data from a scanned file with the following 4 fields: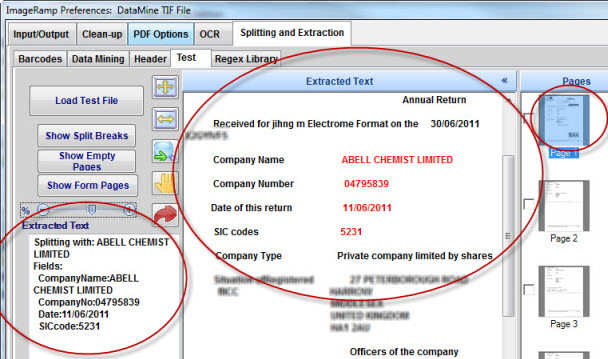
- Company Name
- Company Number
- Date
- SIC Code
We will also be using the Company Name to split individual companies from the OCR’d multipage document and explain a couple of the regular expressions used in this example. A company might use this to scan a large stack of invoices and split the file every time a new company name is located using the regex scripts.
To try this example yourself, download a demo copy of ImageRamp Batch from ImageRamp Downloads. The pre-configured data mining project will allow you to execute this example.
First we are going to define the regex to perform document splitting when a new Company Name is located in ImageRamp’s Splitting and Extraction’s Data Mining submenu as shown below.
For this we use the regex (?<=\bCompany\s*Name\s+\b)[a-z0-9\(\) ]*, and check the “Split if Matched” option. Let’s break this down:
(?<=\bCompany\s*Name\s+\b) – The ?<= portion instructs the regex engine to match but not capture the data. The remaining portion instructs the engine to locate the words “Company Name" where both “Company” and “Name” are at word boundaries “\b”. We are simply using this as a data locator to identify the actual company name that follows.
[a-z0-9\(\) ]* - This portion locates any characters in the class a-z,0-9 and literal parentheses. The “*” will capture as many characters as possible.
The Index Fields section of the Data Mining submenu allows us to extract the metadata or index data from our document.

Remember in our example we identified CompanyName, CompanyNo, Date and SICcode as the index information we want to capture. So here we are extracting the date field using the regex (?(?<=\bDate of this return\s+\b)\d{2}/\d{2}/\d{4}). Let’s again look at what each part of the regex is doing:
? - This portion is allocating a name of “Date” to the rest of the expression which we can use later to refer to the captured portion of the data.
(?<=\bDate of this return\s+\b) – As in the company name example, we are using the words “Date of this return ” to locate the data to be extracted.
(\d{2}/\d{2}/\d{4}) – This portion is used to extract the actual date, \d{2} capture exactly 2 digits followed by a literal “/”, this is repeated for the month and finally \d{4}, capture exactly 4 digits for the year. Usually we would use a more flexible regex for the date to capture multiple formats such as dd-mm-yy or dd-mmm-yyyy, but in this instance we know the format of the date will be uniform and can therefore simplify the expression.
Hopefully we have demonstrated the immense power of using regular expressions to extract data from both structured and unstructured data.
Do you have a data extraction project that we can help with? Did you know we also offer regex professional services for our products?
References/Further Reading
http://en.wikipedia.org/wiki/Regular_expression
http://www.regular-expressions.info/