 What is Document Indexing?
What is Document Indexing?
Learn about Indexing Scans into Document Management Solutions
Indexing is the process of tagging or associating information with a file so it can be used for search and retrieval purposes later. Indexing creates the “searchable” information that users will later use to find documents. The index information is stored or integrated into a database or document/records management system which provides a framework for users to locate the required documents.
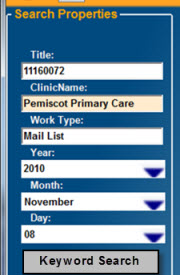 There are two types of indexing. Full-text indexing is just what the name implies; all the text of the document is indexed. When specific words or descriptions are indexed to create the searchable index fields, the information is referred to as “metadata.”
There are two types of indexing. Full-text indexing is just what the name implies; all the text of the document is indexed. When specific words or descriptions are indexed to create the searchable index fields, the information is referred to as “metadata.”
Why Implement Document Management with Document Indexing
The benefits of implementing a document management system are well recognized. Improvements in efficiencies and costs are realized in financial, legal and employee areas.
Great care should be taken to design an efficient indexing scheme. If the process is not designed correctly at the outset, trying to rectify it later can be both difficult and costly. And in some environments such as legal, the cost of not locating a key document can be monumental.
How to Extract Data with Intelligent Data Capture Software
There are a variety of methods and technologies used to extract this data from scanned documents. The following can all play a role in capturing your index information.
- Barcodes
- Content Data Mining
- Optical Character Recognition (OCR)
- Zonal OCR
- Drag and Drop OCR

- Manual Entry
Barcodes and Indexing
Intelligent data capture software can extract data from barcodes to create and send index information to a document management system. Barcodes can also be used for many other purposes such as file naming, splitting, bookmarking and routing.
Learn more at What can barcodes do for me?
Content Data Mining
 Files that contain text can be mined using various data mining techniques. If your documents are scanned pages, you can use full page (text) OCR tools, to turn them into files that can take advantage of this. PDF print streams is another method used to produce the source data for invoice runs or other AP/AR functions that can then be mined for data and document splits. Or existing text-based office documents such as spreadsheets and word documents can also be mined using these techniques. The use of regular expression scripts (regex) has found its way into this arena by providing a powerful tool to help identify keywords or the actual string of text that is desired for capture. The scripting process can look for words with specific characters, lengths, character types, or preceding keywords.
Files that contain text can be mined using various data mining techniques. If your documents are scanned pages, you can use full page (text) OCR tools, to turn them into files that can take advantage of this. PDF print streams is another method used to produce the source data for invoice runs or other AP/AR functions that can then be mined for data and document splits. Or existing text-based office documents such as spreadsheets and word documents can also be mined using these techniques. The use of regular expression scripts (regex) has found its way into this arena by providing a powerful tool to help identify keywords or the actual string of text that is desired for capture. The scripting process can look for words with specific characters, lengths, character types, or preceding keywords.
Regex can also play a role in Index Field Validation. If an inventory item should contain three alpha characters followed by five numbers, advanced indexing solutions can use regex to recognized this pattern and reject all documents with items not meeting this rule. The document can be tagged for manual inspection before further index processing is done
Optical Character Recognition and Indexing
W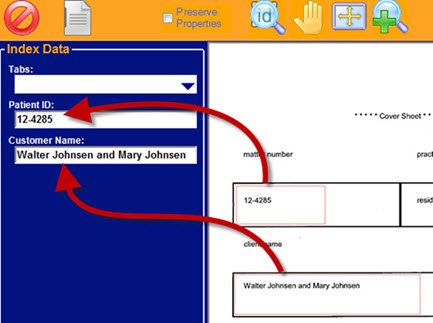 ith OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing.
ith OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing.
With zonal OCR, document areas are specifically identified for OCR capture. Additionally, drag-and-drop OCR allows an operator to highlight document text which is automatically OCR'd and dropped into index fields.
Learn more about automated indexing at ImageRamp.
With most data capture solutions to create a full-text index, users simply select the output file format as a “searchable PDF.” This uses OCR technology to create a PDF file with two layers, an image layer and a text layer that can be used for full-text searching. Your application may label this as “make searchable”, “apply OCR”, “text-under-image” or “searchable PDF.”
Integrating Information into a Document Management
Once index information is captured, it can easily be shared with most databases or document management or EMR/EDR/HER systems from an intelligent capture system. Standard output such as a CSV or XML files can be imported or integrated with these systems to incorporate the index information.
Scan Once, Index Many
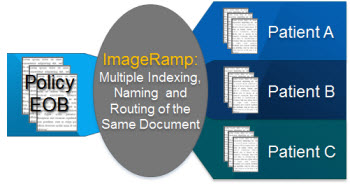 Used to process EOB's or other records where the same document needs to be in multiple patient records or places. Advanced data capture solutions such as ImageRamp allow the operator to easily scan the EOB once, index the different patients' information via an onscreen keyboard, drag-and-drop OCR, or barcode reading methods, and route to the appropriate patients' records with little to no intervention. Learn more at Flexible Indexing for Medical and Dental Records.
Used to process EOB's or other records where the same document needs to be in multiple patient records or places. Advanced data capture solutions such as ImageRamp allow the operator to easily scan the EOB once, index the different patients' information via an onscreen keyboard, drag-and-drop OCR, or barcode reading methods, and route to the appropriate patients' records with little to no intervention. Learn more at Flexible Indexing for Medical and Dental Records.