 Understanding Document Scanning Requirements
Understanding Document Scanning Requirements
If you are new to business scanning, there are a number of decisions to be made before setting up your scanning process. In this article, we discuss fundamental issues you need to understand to make the best decisions for your scanning workflow.
Should I Scan in Duplex/Simplex Mode?
Should the documents be scanned single or double sided? This may seem obvious, but there can be some confusion. You may definitely not want documents scanned in duplex mode where the rear of the document only contains terms and conditions such as on purchase invoices. On the other hand, if the documents have high legal importance you may want every conceivable item of information captured including small signatures or notes on the rear of a document.
What is Scanning Resolution and Why Does it Matter?
Resolution is expressed as the number of dots per inch (dpi) or less frequently pixels (pixel refers to picture element) per inch (ppi) which make up the image or really at which the image is sampled, the following picture illustrates this:
This picture contains two images, a “0” as a grayscale image and an “x” as black and white.
Two things to note here:
- If we halved the size of the grid in both the horizontal and vertical direction (doubled the resolution) the square pixels we see would appear smoother and produce a better quality image, the inverse would be true if we doubled the size of the squares.
- If we kept the squares the same size but reduced the size of the characters significantly, the size of the squares would make it hard to resolve the image, in other words the resolution is insufficient.
Therefore this tells us two things about resolution:
- The higher the resolution, the better the quality the image
- If we have small characters then we should increase the resolution to capture them effectively
One thing this doesn’t necessarily make obvious is that as the resolution is increased, the file size will increase. And in turn your costs will increase as the scanning time (labor costs) and file storage (disk storage requirement) increase.
The resolution a document is scanned at is generally determined by it’s intended use, here are some typical examples:
- Web graphic – 96 dpi
- Standard archive document – 200 dpi
- Document required for optical character recognition (OCR) – 300 dpi
- Plans/drawings for vectorization – 400 dpi
- Documents required for historical archiving – 600 dpi
Some documents such as pre-press photographs require even higher resolutions but are beyond the scope of this article.
Should I Scan in Color, Grayscale or Black and White?
For most archiving requirements (and the majority of scanning requirements) black and white will generally be the choice as it forms the color of most business documents and can be highly compressed to produce small sized files.
Black and White
Documents scanned in black and white are always (internally within the scanner) changed to grayscale. The image then has a process known as thresholding applied to produce the black and white image. Thresholding simply determines when a pixel should be a black or white pixel.
Grayscale
Grayscale is used when the tone of the image contains either color or grayscale data and the tone of the image needs to be retained i.e. photographs or shaded graphics.
Color
Color is obviously used when the image contains color data, however some users will only wish to retain important color information for example land boundaries or graphical data, and not letterhead logos, highlighters etc.
Generally speaking the following applies to the storage requirements of color grayscale and black and white images:
- Black and white requires 1 bit of data to represent a single dot or pixel
- Grayscale requires 8 bits of data to represent one pixel
- Color requires 24 bits of data to represent on pixel (8 bits for each channel, Red, Green and Blue)
So, a grayscale image is usually 8 times larger than a black and white image and a color document will require 24 times as much storage as a black and white.
What File Format Should I Create with my Scans?
Generally speaking file formats fall into one of the following categories:
- TIFF
- JPEG
There are many file formats other than these but these are the most commonly required formats for scanning.
TIFF
TIFF (Tagged Image File Format) can be used for black and white, grayscale or color documents although it is most often used for black and white documents.
The Tag part of Tagged Image File Format refers to information in the header of the file that provides applications (viewers/printers etc) with information about items such as resolution and color space.
TIFF is a well-established file format standard that supports multiple pages and can be interpreted correctly by most applications although this is not true when it comes to certain color implementations.
You may have heard of (or see specifications referring to) TIFF Group 4 or Group IV. The Group 4 part refers to a compression method used for black and white images only. Group 4 is a lossless compression format which means that when the image is compressed and decompressed none of the original data is lost.
JPEG
JPEG (Joint Photographics Expert Group) is really a file compression method rather than a file format but JPEG/Exif and JPEG/JFIF (file formats) are generally referred to as JPEG.
JPEG is generally what is referred to as lossy compression, that is, some of the data is lost during compression however it provides good compression ratios for grayscale and color images. If a low level of compression is used it is not usually perceived by the human eye, high compression levels are noticeable please see below;

JPEG is a good format for color images and photographs. It does not support multi-page formats. A lossless version of JPEG does exist but is not well supported by many applications.
This file format was developed by Adobe and became popular due to the free reader that Adobe distributed. PDF file format is most often used when more advanced features are needed within the file such as embedded OCR, hyperlinking, digital signing and other security features.
PDF files supports color, grayscale and black and white images (generally stored using Group 4 and JPEG compression although other formats are supported) and is commonly specified when OCR is a requirement. It is a common ‘office” format.
Many scanning applications can create searchable PDF files. Here, the scanner applies OCR technology to make the file text searchable. Your application may label this as “make searchable”, “apply OCR”, “text-under-image” or “searchable PDF.” If selected, your file will be text searchable within the Acrobat viewer and many other programs that search PDF files
Another PDF variation is PDF/A. PDF/A is an ISO-standard for digital preservation or archiving of electronic documents. It differs from standard PDF by omitting features not necessary for long-term archiving, such as font linking. PDF/A is growing in use in international government and industry segments, including legal systems, libraries, newspapers, and regulated industries.
What are my Indexing Requirements?
Document indexing (sometimes referred to as metadata) enables a user to quickly and efficiently locate documents, either through a folder structure, database or electronic document management system.
Great care should be taken to design an efficient indexing scheme. If the design is not devised correctly at the outset, trying to rectify it later can be both difficult and costly. Sometimes it makes sense to replicate the current manual method for document location to create a familiar, but faster system.
Indexing can usually be done manually with most scanning applications and some can automate indexing functions by using technologies such as:
- Barcode recognition
- OCR
- Batch processing
Where these methods can be used over manually keying, these methods can provide substantial savings.
Barcodes and Indexing
Intelligent data capture software can extract data from barcodes to create and send index information to a document management system.

Learn more at What can barcodes do for me?
Optical Character Recognition and Indexing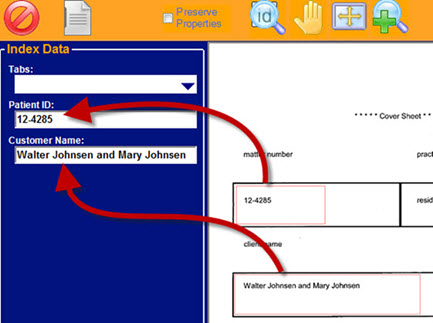
With OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing.
With zonal OCR, document areas are identified for automatic OCR capture. Additionally, drag-and-drop OCR allows an operator to highlight document text which is automatically OCR'd and dropped into index fields.
Learn more about automated indexing at ImageRamp.
Here are some tips for using OCR
- Scan at 300 dpi for greater accuracy and ensure that small text is captured.
- Limit the use of color on documents.
- Pre-process the image with image enhancement software (available in many data capture products, learn more).
Batch Processing Scanned Documents
Intelligent data capture solutions often use batch processing that lets you process a whole folder of documents at a time. Some products can “watch folders,” and process files as they are scanned into the folder. Processing can include indexing, file routing, file splitting, and cleaning/enhancing the scans. Learn more at ImageRamp Batch.
What Do I Need to Know About Document Preparation and Estimating Volumes?
Preparation, quality control and indexing are the most time consuming elements of any scanning job and usually the most costly
Typically a good operator can prepare 750-1000 documents per hour, however a number of factors may drop throughput to 300 or 500. To determine a very rough estimate of typical turnaround times use the following calculation;
Preparation Time Hours = Number of documents (see first section) / 750
Scanning Time Hours = Number of documents / 2500
Indexing Time Hours (assuming basic indexing)= Number of documents / 250
OCR recognition Hours = Number of documents / 2000
These are of course based upon one operator and assume no sophisticated finishing operations but it will give you an indication. It is always advisable to get a representative sample and test.
Factors that Influence Scanning Preparation

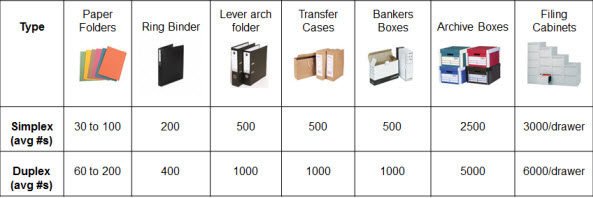
Guidelines for Estimating your Volume of Paper
Documents are often held in a variety of storage containers and the following will provide a typical estimate of the quantities in each.
Can I Build a Path to a Document Management System?
Capturing and indexing your documents into your file system is often a first step towards implementing a document management platform. A capture system can be combined with a simple search and retrieval system or it can be used as the tool to feed the documents into a sophisticated document management system such as Laser Fiche, Documentum, Dentrix or Epic.
Intelligent capture products such as ImageRamp may serve both paths. ImageRamp has its own built-in database, so it works as a simple archiving solution right out of the box or captured information can be integrated with your existing document management or EMR/EHR system.
Using robust technologies such barcodes, OCR, image cleanup, batch processing and regex, users can minimize labor costs while capturing their paper documents. These technologies aid in indexing, file naming, pdf bookmarking, file routing and more.