How to Improve OCR Accuracy with Document Cleanup and Zone Alignment
| Converting unintelligent scanned image data into readable text is a process called Optical Character Recognition (OCR) or Intelligent Character Recognition (ICR). Various techniques have been available and results can vary greatly between packages and more importantly, the scanning process. Image Quality, Zone preparation, multi-engine voting, Zone alignment and regular expressions offer ways to greatly improve the accuracy. |  |
|
One underlying issue is that the quality of the source image and how it is prepared before the OCR engines take over is a very important and often overlooked part of the process. This article describes the considerations you should take when looking to convert image data into intelligent and searchable assets. If you are extracting text for indexing and naming purposes, OCR Zone Processing is used to turn specific regions into index fields in your database. |
Download and use our Free ImageRamp tools for Document Assembly, OCR, barcode page creation and more valuable tools. No registration or obligations. |

With increased deployment of document scanning solutions, image enhancement technology becomes increasingly important.
The OCR Process of Scanned Documents
Many users are scanning to PDF or TIFF and creating searchable files based on OCR (Optical Character Recognition) engines. OCR is defined as “the machine recognition of printed characters” by PC Magazine’s Encyclopedia. OCR uses complex mathematical algorithms and pattern recognition to “read” the image and translate it into text.
The scanning device or scanning software may label full-text indexing options as “make searchable”, “apply OCR”, “text-under-image” or “searchable PDF”. These options create files with two layers, an image layer and a text layer for full-text searching and text mining. The text layer becomes the searchable element upon which the search and retrieval or document management system will rely.
OCR Accuracy and Implementation
 As you can surmise, having the most readable image for the OCR engine to process is critical. Since its development in the 1970’s OCR accuracy has greatly improved. Not only has accuracy improved; OCR has expanded to recognize a variety of languages and symbols.
As you can surmise, having the most readable image for the OCR engine to process is critical. Since its development in the 1970’s OCR accuracy has greatly improved. Not only has accuracy improved; OCR has expanded to recognize a variety of languages and symbols.
Your acceptable level of OCR accuracy will of course depend on your environment. Typically, legal and health industries will have higher accuracy requirements than a marketing or archival implementation.
Optimizing for OCR Accuracy and Correction
Optimizing your environment or implementation for the highest OCR accuracy generally is divided into two phases, pre-scanning and during scanning
In the pre-scanning phase, users may be able to control some aspects that impact OCR accuracy. Document or form design, font selection, and color selection all impact OCR accuracy. Designing forms or setting document standards specifying adequate white space, limited lines, limited colors, and monospace fonts like Courier or san serif fonts such as Helvetica in at least 10-13 points, are ideal.
 During the scanning process, the resolution selected and the “cleanness” of the scanned image impacts accuracy. Documents should be scanned at a minimum of 300 dots per inch for accurate OCR. Some capture software also employs validation technology or rules-based processing.
During the scanning process, the resolution selected and the “cleanness” of the scanned image impacts accuracy. Documents should be scanned at a minimum of 300 dots per inch for accurate OCR. Some capture software also employs validation technology or rules-based processing.
OCR with validation during processing involves using technology to automatically validate against data sources or employing business rules. For instance if an inventory item should contain three alpha characters followed by five numbers, all documents with item numbers that are not identified in the OCR process with that scheme during the capture process may be tagged for manual inspection before further processing is done.
After optimizing the OCR in the first two phases, some people can live with the accuracy of the OCR results. They may be ok relying on fuzzy search filtering and keyword indexing to provide an acceptable search implementation and do not need any further processing. But, some users (those legal and health implementations in particular) may still require corrections in the final phase, post-scanning. Error correction must be done manually at the cost of additional labor.
Image Enhancement to Improve OCR Accuracy
As mentioned previously OCR accuracy is improved if the scanned image is cleaned and enhanced. Basic clean and enhancement functions included with most scanning applications increase the accuracy and reliability of the information extracted from the scans. Accuracy is further improved with advanced clean up functions such as those found in DocuFi’s ImageRamp. Besides increasing OCR accuracy, cleaning and enhancing images generally creates smaller files which can be a advantage in file storage, retrieval and loading.
ImageRamp and Image Enhancement
ImageRamp is DocuFi’s intelligent document and data capture solution that works with your existing scanning investment of TWAIN devices or with integrated touchscreen scanners for walk up network document capture. With ImageRamp, select from a sophisticated set of image enhancement features more commonly found in production scanning equipment, or use the interactive tools to adjust your document threshold using our unique rollback feature. We incorporate dual stream scanning and preserve a greyscale original which you can use to obtain optimal image clarity.
Adaptive Thresholding
Adaptive thresholding technology assists in cleaning “dirty” documents or documents that have a colored background which interferes with the foreground data. This can be especially helpful in cleaning forms to improve the OCR accuracy. Most scanner and capture software can apply basic thresholding technology. ImageRamp uses Adaptive Thresholding with advanced algorithms and Sensitivity settings allowing you to optimize the thresholding for your documents.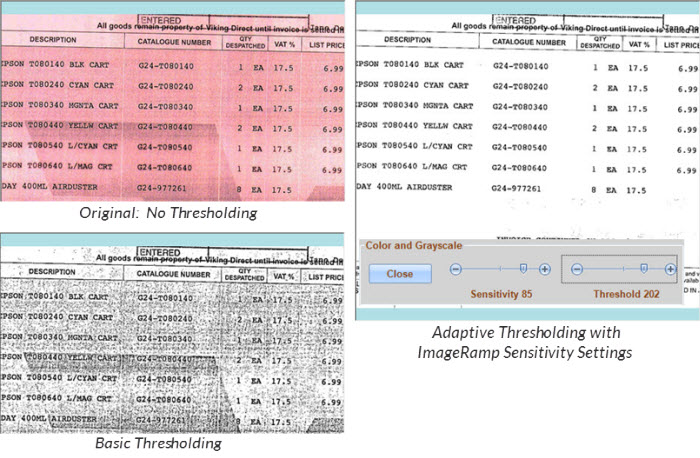
Smooth Text
 Selecting the Smooth Text option smoothes the edging of text. Smoothing text fills small pits in the edges of a character and removes small bumps on the edges. This effort can improve OCR accuracy, improve legibility, and reduce storage needs.
Selecting the Smooth Text option smoothes the edging of text. Smoothing text fills small pits in the edges of a character and removes small bumps on the edges. This effort can improve OCR accuracy, improve legibility, and reduce storage needs.
Reset Margins
 The Reset Margins option searches and resizes the document based on the outermost located raster data or pixels. It is important to also perform Straighten Page, Remove Noise, and other functions to eliminate unnecessary border noise which could be used in error as the outermost rater or pixels for cropping.
The Reset Margins option searches and resizes the document based on the outermost located raster data or pixels. It is important to also perform Straighten Page, Remove Noise, and other functions to eliminate unnecessary border noise which could be used in error as the outermost rater or pixels for cropping.
Deskew or Straighten Page
Checking the Straighten Page option simply properly aligns documents that have been skewed. Using detected text as the basis for alignment, this tool is designed to work with scanned office documents and eliminate rescans. This will correct pages that are misfed during scanning and if the documents scanned are actually skewed copies.
 Remove Lines
Remove Lines
The Remove Lines option is helpful to remove gridlines to accurately capture the text in the grid. This can be especially helpful in capturing forms such as invoices.
Remove Noise or Despeckle
Whether your scanned image is contaminated with dust or specks or a bad original, despeckling can clean the image significantly and improve OCR interpretation. This option removes extraneous black specks and fills in white holes on black areas of an image.
Autorotate and Rotate Pages
With Auto Rotate selected, ImageRamp automatically evaluates orientation based on the text and automatically rotates misoriented pages. If any of the “degree” rotations are selected, ImageRamp will rotate all pages based on the selection.
Preview and Testing
ImageRamp offers significant preview and testing options allowing administrators to pretest their documents and fine-tune settings to ensure the image is optimized for OCR. Additionally ImageRamp offers PDF or TIFF output which may differ in OCR accuracy. With testing against your specific documents, settings and file output can be optimized to obtain the most accurate OCR results for you.
To Wrap It Up
Whether you are creating full-text indexes or text mining for information to split, name, and route files, OCR accuracy is crucial. To optimize your scanning success:
- Use Good Pre-processing Techniques
Good pre-processing can be as important as the scanning technologies involved. Encourage accuracy by setting document procedures and guidelines to:- Use adequate white space
- Limit lines and gridlines
- Limit the use of color
- Use OCR friendly fonts and sizes
- Scan at 200 or 300 DPI Minimally
- Use an Intelligent Document and Data Capture Solution
Software such as ImageRamp uses advanced cleanup and validation technology with preview and testing mechanisms.
Image Enhancement Improves OCR accuracy of Scanned documents