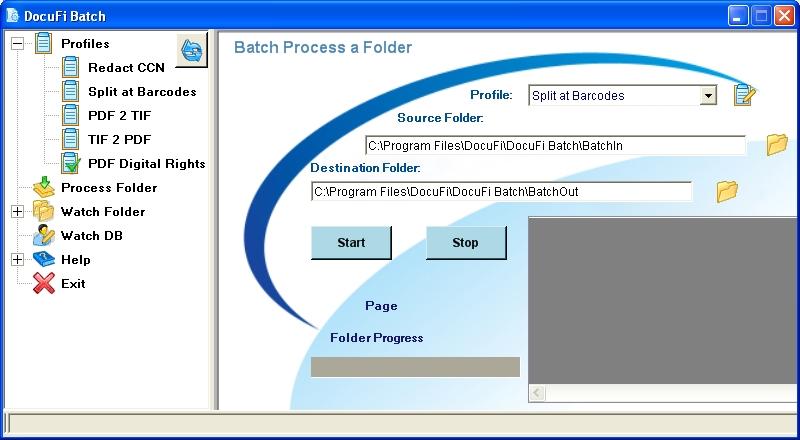
Batch Processing a Folder of Scanned PDF Files
You can begin using ImageRamp Batch on any of your profiles by the Process Folder node in the interface. The default will be to load the last profile you had selected which is designated by the icon: Getting Started You can now use a drop down to select a desired profile with the specific instructions on what should be done to this folder (file naming, splitting, clean-up, DRM, etc. You can edit your profile from this screen by selecting the edit icon. Browse to your Source folder and Destination Folder then Click the Start button to initiate the job on your desired folder.