How To Guides
How to Improve Document Scanning Zone OCR Accuracy
| Zonal OCR (Optical Character Recognition) is a technique used to capture specific items from your documents. Invoice numbers, dates, client names, etc., all exist in freeform (unstructured) or fixed (structured documents. In this article, we will explore the techniques available to help improve the accuracy of the zones to realize the best results. |  |
|
If you are extracting text for indexing or file naming purposes, OCR Zone Processing is used to turn specific document regions or zones, into usable data. Some of the most influencial capabilities include:
|
Download and use our Free ImageRamp tools for Document Assembly, OCR, or barcode separation page creation. No registration or obligations. |

Zone alignment
Often, the location of a zone moves from image to Image. This is due to changes in the form types, or even border issues with scanning. Auto cropping can help to some degree, but too often, zones move ever so slightly to make fixed zones impossible to use. Some tools incorporate "Anchor Words" which are high accuracy words that are used as an Anchor point. A general area of interest is defined on the document and the Anchor Word is used to align the zones to it. As long as there is consistency to a anchor word, your zone positions should improve greatly with these kinds of tools. Only high confidence words should be used. In our example, high confidence words are shown along with the selected anchor word (Part). 
Zone Image Improvement
Since zone images are used temporarily for text extraction purposes, they can be further processed without consideration of the saved file. Some Image Processing options that can effect the OCR results include:
- Line Removal will remove grid lines that sometimes interfere with the OCR or result in additional characters recognized such as an "I". More advanced systems can remove lines that intersect with text and repair the common area where the characters intersect with the removed line.
- Edge smoothing can be used to deal with "spurs" and other edge issues on documents.
- Adaptive Thresholding involves two dimensional image processing can also be used where neighboring pixels are incorporated into sophisticated algorithms to help smooth out the characters.
- Pixel Expansion or thickening is helpful for lightly scanned images. The pixels are expanded in 4 or 8 directions to help the OCR recognize the objects.

Using multiple OCR engines and word confidence
Some systems use a confidence scores on the resulting words captured in a OCR Zone. When combined with multiple OCR engines, you can take the best results to obtain the higher accuracy. OCR engines use different techniques to match characters and deal with broken and disjointed image data. Passing images through each engine, scoring the confidence, then using the best scoring engine can help improve accuracy or missed data when one engine fails on a zone.
Using Regular Expressions
With the use of regular expressions, you can expand the search region to look for keywords or have rules that only return the exact character string. If we have a zone in which we want to extract a zip code, we can look for the numeric sequence of 5 numbers or 5 numbers followed by a dash and

To Wrap It Up
When extracting text from an image, OCR Accuracy, Zone placement and post processing is crucial. To optimize your scanning success:
- Use Good Pre-processing Techniques
Good pre-processing can be as important as the scanning technologies involved. Encourage accuracy by setting document procedures and guidelines to:- Use adequate white space
- Limit lines and gridlines
- Limit the use of color
- Use OCR friendly fonts and sizes
- Scan at 200 or 300 DPI Minimally
- Use an Intelligent Document and Data Capture Solution
Software such as ImageRamp uses advanced cleanup and validation technology with preview and testing mechanisms.
 How to automate naming and splitting of scanned delivery notes
How to automate naming and splitting of scanned delivery notes
Learn how to improve zone processing using advanced settings in ImageRamp Batch
Extracting content from existing scanned documents can save significant time when done right. How can we obtain the highest degree of automation out of our scanned documents?
Delivery Tickets Use Case -
In this scenario, a company scans several delivery tickets at the same time. The tickets contain a unique text identifier including a date and three part numbers encased in square brackets. Since these are newly scanned, OCR processing is required to add intelligence to the scanned image files. Each delivery note has a specific string of text that is contained within square brackets ie "[[028573-502838-928439]]. And the desire is to automate the naming of the resulting delivery tickets.
Some of the common issues inherent with this process are multiple.
- Inconsistency of the location of the text,
- OCR tends to misread numbers as letters (1 as I, 5 as S, 8 as B and 0 as O).
- It is costly to scan each document individually, so splitting is a desired output.
We will walk through the steps of ensuring the highest degree of automation with ImageRamp in this article.
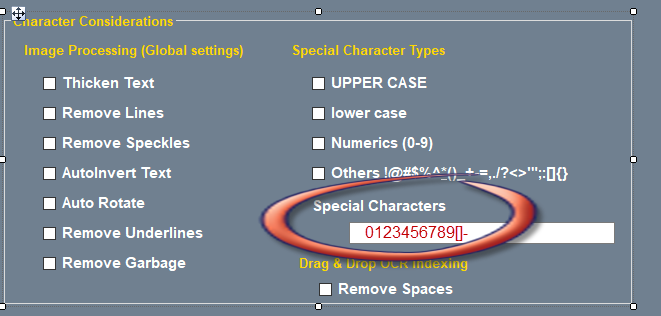
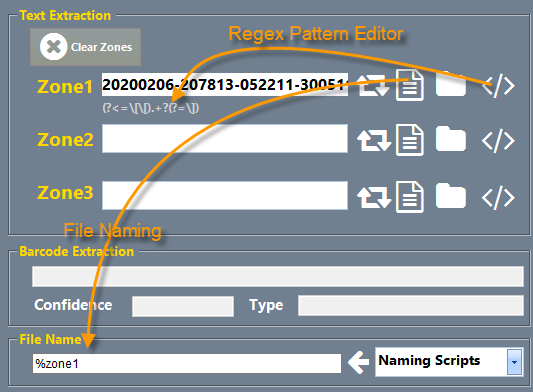
| Step 1 OCR Fine Tuning - One of the first things to do is to set the OCR engine to only recognize specific characters. All text identified in the region of interest will only result in these characters. You can enter any specific characters or use the built in character types found in the OCR Settings panel. | Step 2 Regular Expressions - We can also take advantage of the uniqueness of the text and Regular Expression. This offers a way to pinpoint the exact text patterns we want to extract. We can be very specific. In this script we are looking for "[[" at the beginning of a string and "]" at the end of the string and extracting everything in between. | Step 3 Define our Zone - Now select the icon to define a rectangular zone from which we will perform the OCR extraction of text. All text will utilize the character definitions defined earlier and will use the regular expression to extract just the specific text we desire. |
 |
 |
 |
|
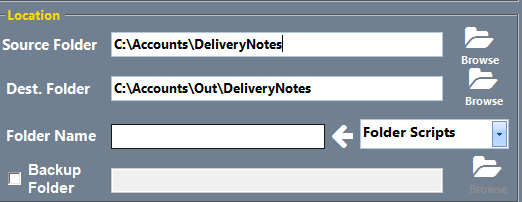
Step 4 - File Naming and paths we can finish the document type configuration by defining how the file is to be named using barcode, system or text extraction keywords, and defining where the files will be coming from and go to. |
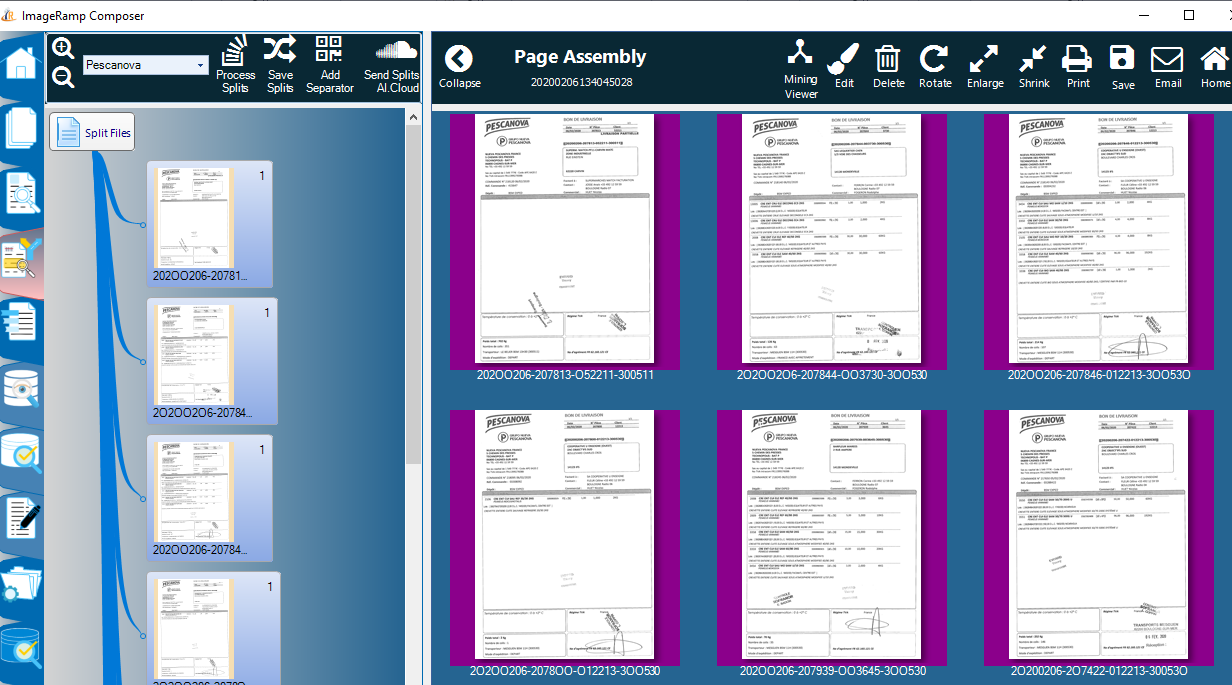
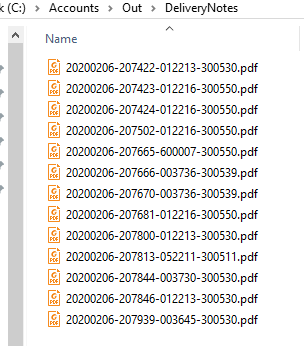
Step 5 - Processing the splits - Once set up, we can now load individual files or set up folder watching to process files. Here we've loaded a 17 page scan and processed the splits in accordance with our newly defined delivery notes document type. | Step 6 - The Processed output - We can now see the results of our processing with all numeric values extracted from the OCR zones. |
 |
 |
 |
Content Data Mining
 Files that contain text can be mined using various data mining techniques. If your documents are scanned pages, you can use full page (text) OCR tools, to turn them into files that can take advantage of this. PDF print streams is another method used to produce the source data for invoice runs or other AP/AR functions that can then be mined for data and document splits. Or existing text-based office documents such as spreadsheets and word documents can also be mined using these techniques. The use of regular expression scripts (regex) has found its way into this arena by providing a powerful tool to help identify keywords or the actual string of text that is desired for capture. The scripting process can look for words with specific characters, lengths, character types, or preceding keywords.
Files that contain text can be mined using various data mining techniques. If your documents are scanned pages, you can use full page (text) OCR tools, to turn them into files that can take advantage of this. PDF print streams is another method used to produce the source data for invoice runs or other AP/AR functions that can then be mined for data and document splits. Or existing text-based office documents such as spreadsheets and word documents can also be mined using these techniques. The use of regular expression scripts (regex) has found its way into this arena by providing a powerful tool to help identify keywords or the actual string of text that is desired for capture. The scripting process can look for words with specific characters, lengths, character types, or preceding keywords.
Regex can also play a role in Index Field Validation. If an inventory item should contain three alpha characters followed by five numbers, advanced indexing solutions can use regex to recognized this pattern and reject all documents with items not meeting this rule. The document can be tagged for manual inspection before further index processing is done
Optical Character Recognition and Indexing
W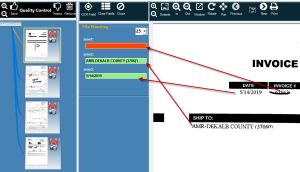 ith OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing. With zonal OCR, document areas are specifically identified for OCR capture. Additionally, drag-and-drop OCR allows an operator to highlight document text which is automatically OCR'd and dropped into index fields.
ith OCR, you can make your image-based file fully text-searchable or extract data from a zone for indexing. With zonal OCR, document areas are specifically identified for OCR capture. Additionally, drag-and-drop OCR allows an operator to highlight document text which is automatically OCR'd and dropped into index fields.
Learn more about automated indexing at ImageRamp.
With most data capture solutions to create a full-text index, users simply select the output file format as a “searchable PDF.” This uses OCR technology to create a PDF file with two layers, an image layer and a text layer that can be used for full-text searching. Your application may label this as “make searchable”, “apply OCR”, “text-under-image” or “searchable PDF.”
I
Turning Content into Data with Intelligent Data Extraction
Extracting your data shouldn’t be like pulling teeth
 As many businesses move to the “nearly” paperless office, they have moved beyond scanning existing paper for storage or archival. Today, businesses demand that the information in their documents is seamlessly available to users. This has led capture software providers to incorporate new and improved technologies so their software “sees” the image, “extracts” the key information and incorporates it into key Enterprise Content Management (ECM), Electronic Medical Records (EMR), Electronic Resource Planning (ERP) or line of business software where it can be shared and used.
As many businesses move to the “nearly” paperless office, they have moved beyond scanning existing paper for storage or archival. Today, businesses demand that the information in their documents is seamlessly available to users. This has led capture software providers to incorporate new and improved technologies so their software “sees” the image, “extracts” the key information and incorporates it into key Enterprise Content Management (ECM), Electronic Medical Records (EMR), Electronic Resource Planning (ERP) or line of business software where it can be shared and used.
Key Elements of Intelligent Data Capture
Three areas are identified as the essence of intelligent data capture.

In the first step, Recognize , capture software must employ technology to turn scanned images into computer-readable text. Next, the software must Extract information by identifying what the important or key information is from the text. And finally, capture software must be able to share or Integrate the key data into ECM, DM, or ERP type systems where the user can consume and use the information.
Recognition: Turning 1’s and O’s Into Text
OCR (Optical Character Recognition)
 OCR is a mature data conversion technology that digitizes text images so that they can be electronically edited, searched, and stored. With OCR you can make your image-based file fully text-searchable or extract select data from it. Full page OCR is used when all content of a document needs to be converted to readable text. With zonal OCR, specific document areas are identified for automatic OCR capture. Additionally, drag-and-drop or rubber band OCR allows an operator to highlight document text which is automatically converted and dropped into index fields.
OCR is a mature data conversion technology that digitizes text images so that they can be electronically edited, searched, and stored. With OCR you can make your image-based file fully text-searchable or extract select data from it. Full page OCR is used when all content of a document needs to be converted to readable text. With zonal OCR, specific document areas are identified for automatic OCR capture. Additionally, drag-and-drop or rubber band OCR allows an operator to highlight document text which is automatically converted and dropped into index fields.
OCR has the greatest impact on the growth of intelligent data extraction and the potential continues to grow as the technologies continue to improve.
Barcode Technology in Data Capture
 Built on proven standards and a successful history, barcode recognition (BCR) offers the most trustworthy recognition technology for data capture. Barcodes identify merchandise and equipment, tag documents and even tag patients in hospital care, all with accuracy that is unmatched by any other classification approach. Barcodes can be used in both structured and unstructured document formats and are far more accurate than OCR.
Built on proven standards and a successful history, barcode recognition (BCR) offers the most trustworthy recognition technology for data capture. Barcodes identify merchandise and equipment, tag documents and even tag patients in hospital care, all with accuracy that is unmatched by any other classification approach. Barcodes can be used in both structured and unstructured document formats and are far more accurate than OCR.
Other Recognition Technologies for Data Capture
ICR (Intelligent Character Recognition)
ICR is a handwriting recognition system that allows fonts and different styles of handwriting to be learned by a computer during processing to improve accuracy and recognition levels. Obviously this technology is not as accurate as OCR, but it does have a limited role in some capture systems and continues to improve in accuracy.
OMR (Optical Mark Recognition)
OMR is the process of capturing human-marked data from document forms such as surveys and tests. Like ICR, lower accuracy limits the application within data capture environments today. Again, the accuracy of this recognition is seeing improvements.
Extract: Locating the Key Information
 After the content has been captured, pattern matching technology identifies the key data or information in the document.
After the content has been captured, pattern matching technology identifies the key data or information in the document.
Regular expressions (regex) provide a fast and powerful method to search, extract and replace specific data found within scanned documents. Regular expressions are essentially a special text string for describing a search pattern. You could think of regular expressions as extremely powerful wildcards.
 Regex’s powerful expressions are extremely flexible and patterns can be constructed to match almost anything. For text commonly found in documents such as dates, SSNs, ZIP codes etc., patterns are freely available on the Internet. Here are some examples:
Regex’s powerful expressions are extremely flexible and patterns can be constructed to match almost anything. For text commonly found in documents such as dates, SSNs, ZIP codes etc., patterns are freely available on the Internet. Here are some examples:
|
ZIP Codes - ^(?!00000)(?<zip>(?<zip5>\d{5})(?:[ -](?=\d))?(?<zip4>\d{4})?)$ |
|
US Phone Number - ^([0-9]( |-)?)?(\(?[0-9]{3}\)?|[0-9]{3})( |-)?([0-9]{3}( |-)?[0-9]{4}|[a-zA-Z0-9]{7})$ |
|
Credit Card - (^(4|5)\d{3}-?\d{4}-?\d{4}-?\d{4}|(4|5)\d{15})|(^(6011)-?\d{4}-?\d{4}-?\d{4}|(6011)-?\d{12})|(^((3\d{3}))-\d{6}-\d{5}|^((3\d{14}))) |
Lookahead and Lookbehind
The Lookahead and Lookbehind features go beyond basic zonal OCR and let you identify and extract data from unstructured documents with data found anywhere on the scan. This entails searching for an identifiable keyword or string, like “PO Number” or related derivatives (Purchase Order Number), and then a word pattern to identify the desired text to capture before or after the specified matching word.
Line Item Extraction
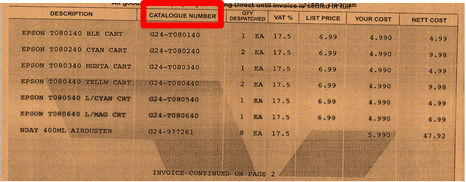
One of the more complex challenges is the need to capture column-based data, or data where the text is not adjacent to a matching word. Often called Line Item Extraction, this technique is used in applications where the desired text to capture is often found below the keyword. For a real world example, here is a partial invoice where you might need to capture the "Catalogue Number“ using Line Item Extraction techniques.
What Can the Capture Software Do with Identified Data?
So once the key data has been identified or “extracted”, how can the capture software add “intelligence”?
- Split Files
A large single file can be split into multiple files based on information extracted from barcodes and content. - Name Files and Folders
Name files, folders and subfolders with extracted information from the file or system information. - Route Files
Route the files to another directory (and even create the folder and subfolder names) using content. - Index
Create indexes from extracted information for the “searchable” fields. - Create PDF Bookmarks
Create PDF bookmarks based on extracted information. - Validate
Data can be validated against business rules to reduce errors.
Integrate: Share, Making Data Available to Users
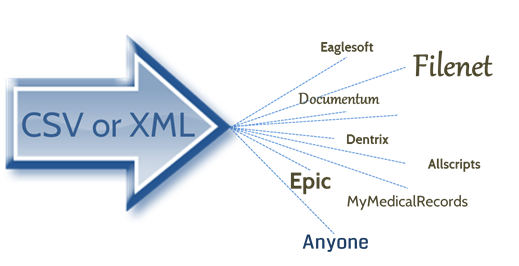
Integration means sharing the information with the user. The key data can be sent to the user's system via standard XML to CSV file. These data transfer standard formats are accepted by virtually any database. The end users' system could be a simple search and retrieval system, a document management system or ECM system or a more specific system such as an ERP system.
What Does the Future Hold for Intelligent Data Capture?
Users will continue to demand increasingly smarter interpretation of their content and push to access real data seamlessly. The technology will see improvements in speed, accuracy and scope. And, as with most information technology trends today, increased mobile and cloud computing will be seen in intelligent data capture. In this environment, information governance and compliance will be tested and companies will need increased technical support to manage the increasing complexity. In summary, the following will characterize the intelligent data capture direction.
- Continued Improvement in Recognition Technologies Including:
OCR expansion to include services like translation
Better accuracy of ICR and OMR
Faster, more accurate results - Increased Mobility Integration For Smart Phones, Tablets, etc
- Increased Cloud Computing Based Services
- Improved Validation Against Complex Business Rules
- Increased Technical Support to Manage the Complexity
- Increased Information Governance and Compliance Issues and Complexity
Learn More
There is no better time to get started than now. Find out about ImageRamp, our capture platform, and send us an email to discuss your capture challenges.
 Flexible Options for Medical and Dental Record Indexing
Flexible Options for Medical and Dental Record Indexing
Medical and dental records have many special document processing needs. With the movement to comply with the Health Information Technology for Economic and Clinical Health (HITECH) Act, many companies and health care organizations have implemented sophisticated EHR systems, while others are just beginning. Along the way some of the special needs of processing medical and dental related documents have been highlighted. One such need is what we call scan once, index many.
Used to process EOB's or other records where the same document needs to be in multiple patient records, scan once index many allows the operator to easily scan the EOB once, index the different patients' information via an onscreen keyboard, drag-and-drop OCR, or barcode reading methods, and route to the appropriate patients' records with little to no intervention. ImageRamp accommodates this processing as well as the traditional scan once, split and index used when a single file may consist of multiple patient records which need to be split, named and routed to the correct patient’s records.

Field Validation Improves Accuracy
 Entering the correct data the first time can save countless hours when trying to locate documents later. Field validation improves accuracy. If a patient record ID should contain three alpha characters followed by five numbers, ImageRamp can use Regular Expressions or regex to recognize this pattern and flag records that do not meet this pattern for interactive operator indexing.
Entering the correct data the first time can save countless hours when trying to locate documents later. Field validation improves accuracy. If a patient record ID should contain three alpha characters followed by five numbers, ImageRamp can use Regular Expressions or regex to recognize this pattern and flag records that do not meet this pattern for interactive operator indexing.
So How Can the Index Data be Identified and Extracted?
Individually or in combination, advanced capture technologies can be used to capture the index information with little or no user intervention. You might be familiar with using barcode information as a proven, mature capture method. Newer methods based on OCR mined text can also greatly automate indexing.
Data mining with re gex provides a fast and powerful method to search and extract specific text strings found within documents. Data identified with regex can be used to index documents as well as name the output files, or even create folders. Regex can also play a role in line item extraction. This extension of data mining is common within invoice forms and other table based documents. With line item extraction, instead of extracting strings of text beside a matching pattern, users may want to obtain data found below the match word in a column type fashion.
gex provides a fast and powerful method to search and extract specific text strings found within documents. Data identified with regex can be used to index documents as well as name the output files, or even create folders. Regex can also play a role in line item extraction. This extension of data mining is common within invoice forms and other table based documents. With line item extraction, instead of extracting strings of text beside a matching pattern, users may want to obtain data found below the match word in a column type fashion.
Built on proven standards and a successful history, barcode recognition offers the most trustworthy recognition technology for data capture. Barcodes identify merchandise and equipment, tag documents patients in hospital care, all with accuracy that is unmatched by any other classification approach. Barcodes can be used in both structured and unstructured document formats. Barcode information can easily be extracted and combined with other information from text mining or system data for index purposes.
Integrating Extracted Index Information
Captured index information can be sent via XML or CSV files to a document or content management system such as an EMR/EHR or EDR system. Popular systems such as Epic and Dentrix can accept these files and integrate the information.

Cloud-based Document Processing and Indexing
Simply send an email with attached or referenced files with natural language instructions on what you want done to the files, and the results are returned. No need for local document processing software or complex interfaces, just email and your files. Use with our DocuFiCloud Service or within your own intranet. Use our patent-pending technology from smartphones, tablets, PCs and more to process scanned files on your device or network or PDF print streams.